Encoding Statistical Independence, Statically
16 Feb 2016Applicative functors are useful for encoding context-free effects. This typically gets put to work around things like parsing or validation, but if you have a statistical bent then an applicative structure will be familiar to you as an encoder of independence.
In this article I’ll give a whirlwind tour of probability monads and algebraic freeness, and demonstrate that applicative functors can be used to represent independence between probability distributions in a way that can be verified statically.
I’ll use the following preamble for the code in the rest of this article. You’ll need the free and mwc-probability libraries if you’re following along at home:
{-# LANGUAGE DeriveFunctor #-}
{-# LANGUAGE LambdaCase #-}
import Control.Applicative
import Control.Applicative.Free
import Control.Monad
import Control.Monad.Free
import Control.Monad.Primitive
import System.Random.MWC.Probability (Prob)
import qualified System.Random.MWC.Probability as MWC
Probability Distributions and Algebraic Freeness
Many functional programmers (though fewer statisticians) know that probability has a monadic structure. This can be expressed in multiple ways; the discrete probability distribution type found in the PFP framework, the sampling function representation used in the lambda-naught paper (and implemented here, for example), and even an obscure measure-based representation first described by Ramsey and Pfeffer, which doesn’t have a ton of practical use.
The monadic structure allows one to sequence distributions together. That is: if some distribution ‘foo’ has a parameter which itself has the probability distribution ‘bar’ attached to it, the compound distribution can be expressed by the monadic expression ‘bar »= foo’.
At a larger scale, monadic programs like this correspond exactly to what you’d typically see in a run-of-the-mill visualization of a probabilistic model:
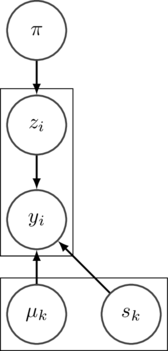
In this classical kind of visualization the nodes represent probability distributions and the arrows describe the dependence structure. Translating it to a monadic program is mechanical: the nodes become monadic expressions and the arrows become binds. You’ll see a simple example in this article shortly.
The monadic structure of probability implies that it also has a functorial structure. Mapping a function over some probability distrubution will transform its support while leaving its probability density structure invariant in some sense. If the function ‘uniform’ defines a uniform probability distribution over the interval (0, 1), then the function ‘fmap (+ 1) uniform’ will define a probability distribution over the interval (1, 2).
I’ll come back to probability shortly, but the point is that probability distributions have a clear and well-defined algebraic structure in terms of things like functors and monads.
Recently free objects have become fashionable in functional programming. I won’t talk about it in detail here, but algebraic ‘freeness’ corresponds to a certain preservation of structure, and exploiting this kind of preserved structure is a useful technique for writing and interpreting programs.
Gabriel Gonzalez famously wrote about freeness in an oft-cited article about free monads, John De Goes wrote a compelling piece on the topic in the excellent A Modern Architecture for Functional Programming, and just today I noticed that Chris Stucchio had published an article on using Free Boolean Algebras for implementing a kind of constraint DSL. The last article included the following quote, which IMO sums up much of the raison d’être to exploit freeness in your day-to-day work:
.. if you find yourself re-implementing the same algebraic structure over and over, it might be worth asking yourself if a free version of that algebraic structure exists. If so, you might save yourself a lot of work by using that.
If a free version of some structure exists, then it embodies the ‘essence’ of that structure, and you can encode specific instances of it by just layering the required functionality over the free object itself.
A Type for Probabilistic Models
Back to probability. Since probability distributions are monads, we can use a free monad to encode them in a structure-preserving way. Here I’ll define a simple probability base functor for which each constructor is a particular ‘named’ probability distribution:
data ProbF r =
BetaF Double Double (Double -> r)
| BernoulliF Double (Bool -> r)
deriving Functor
type Model = Free ProbF
Here we’ll only work with two simple named distributions - the beta and the Bernoulli - but the sky is the limit.
The ‘Model’ type wraps up this probability base functor in the free monad, ‘Free’. In this sense a ‘Model’ can be viewed as a program parameterized by the underlying probabilistic instruction set defined by ‘ProbF’ (a technique I described recently).
Expressions with the type ‘Model’ are terms in an embedded language. We can create some user-friendly ones for our beta-bernoulli language like so:
beta :: Double -> Double -> Model Double
beta a b = liftF (BetaF a b id)
bernoulli :: Double -> Model Bool
bernoulli p = liftF (BernoulliF p id)
Those primitive terms can then be used to construct expressions.
The beta and Bernoulli distributions enjoy an algebraic property called conjugacy that ensures (amongst other things) that the compound distribution formed by combining the two of them is analytically tractable. Here’s a parameterized coin constructed by doing just that:
coin :: Double -> Double -> Model Bool
coin a b = beta a b >>= bernoulli
By tweaking the parameters ‘a’ and ‘b’ we can bias the coin in particular ways, making it more or less likely to observe a head when it’s inspected.
A simple evaluator for the language goes like this:
eval :: PrimMonad m => Model a -> Prob m a
eval = iterM $ \case
BetaF a b k -> MWC.beta a b >>= k
BernoulliF p k -> MWC.bernoulli p >>= k
‘iterM’ is a monadic, catamorphism-like recursion scheme that can be used to succinctly consume a ‘Model’. Here I’m using it to propagate uncertainty through the model by sampling from it ancestrally in a top-down manner. The ‘MWC.beta’ and ‘MWC.bernoulli’ functions are sampling functions from the mwc-probability library, and the resulting type ‘Prob m a’ is a simple probability monad type based on sampling functions.
To actually sample from the resulting ‘Prob’ type we can use the system’s PRNG for randomness. Here are some simple coin tosses with various biases as an example; you can mentally substitute ‘Head’ for ‘True’ if you’d like:
> gen <- MWC.createSystemRandom
> replicateM 10 $ MWC.sample (eval (coin 1 1)) gen
[False,True,False,False,False,False,False,True,False,False]
> replicateM 10 $ MWC.sample (eval (coin 1 8)) gen
[False,False,False,False,False,False,False,False,False,False]
> replicateM 10 $ MWC.sample (eval (coin 8 1)) gen
[True,True,True,False,True,True,True,True,True,True]
As a side note: encoding probability distributions in this way means that the other ‘forms’ of probability monad described previously happen to fall out naturally in the form of specific interpreters over the free monad itself. A measure-based probability monad could be achieved by using a different ‘eval’ function; the important monadic structure is already preserved ‘for free’:
measureEval :: Model a -> Measure a
measureEval = iterM $ \case
BetaF a b k -> Measurable.beta a b >>= k
BernoulliF p k -> Measurable.bernoulli p >>= k
Independence and Applicativeness
So that’s all cool stuff. But in some cases the monadic structure is more than what we actually require. Consider flipping two coins and then returning them in a pair, for example:
flips :: Model (Bool, Bool)
flips = do
c0 <- coin 1 8
c1 <- coin 8 1
return (c0, c1)
These coins are independent - they don’t affect each other whatsoever and enjoy the probabilistic/statistical property that formalizes that relationship. But the monadic program above doesn’t actually capture this independence in any sense; desugared, the program actually proceeds like this:
flips =
coin 1 8 >>= \c0 ->
coin 8 1 >>= \c1 ->
return (c0, c1)
On the right side of any monadic bind we just have a black box - an opaque function that can’t be examined statically. Each monadic expression binds its result to the rest of the program, and we - programming ‘at the surface’ - can’t look at it without going ahead and evaluating it. In particular we can’t guarantee that the coins are truly independent - it’s just a mental invariant that can’t be transferred to an interpreter.
But this is the well-known motivation for applicative functors, so we can do a little better here by exploiting them. Applicatives are strictly less powerful than monads, so they let us write a probabilistic program that can guarantee the independence of expressions.
Let’s bring in the free applicative, ‘Ap’. I’ll define a type called ‘Sample’ by layering ‘Ap’ over our existing ‘Model’ type:
type Sample = Ap Model
So an expression with type ‘Sample’ is a free applicative over the ‘Model’ base functor. I chose the namesake because typically we talk about samples that are independent and identically-distributed draws from some probability distribution, though we could use ‘Ap’ to collect samples that are independently-but-not-identically distributed as well.
To use our existing embedded language terms with the free applicative, we can create the following helper function as an alias for ‘liftAp’ from ‘Control.Applicative.Free’:
independent :: f a -> Ap f a
independent = liftAp
With that in hand, we can write programs that statically encode independence. Here are the two coin flips from earlier (and if you’re applicative-savvy I’ll avoid using ‘liftA2’ here for clarity):
flips :: Sample (Bool, Bool)
flips = (,) <$> independent (coin 1 8) <*> independent (coin 8 1)
The applicative structure enforces exactly what we want: that no part of the effectful computation can depend on a previous part of the effectful computation. Or in probability-speak: that the distributions involved do not depend on each other in any way (they would be captured by the plate notation in the visualization shown previously).
To wrap up, we can reuse our previous evaluation function to interpret a ‘Sample’ into a value with the ‘Prob’ type:
evalIndependent :: PrimMonad m => Sample a -> Prob m a
evalIndependent = runAp eval
And from here it can just be evaluated as before:
> MWC.sample (evalIndependent flips) gen
(False,True)
Conclusion
That applicativeness embodies context-freeness seems to be well-known when it comes to parsing, but its relation to independence in probability theory seems less so.
Why might this be useful, you ask? Because preserving structure is mandatory for performing inference on probabilistic programs, and it’s safe to bet that the more structure you can capture, the easier that job will be.
In particular, algorithms for sampling from independent distributions tend to be simpler and more efficient than those useful for sampling from dependent distributions (where you might want something like Hamiltonian Monte Carlo or NUTS). Identifying independent components of a probabilistic program statically could thus conceptually simplify the task of sampling from some conditioned programs quite a bit - and that matters.
Enjoy! I’ve dumped the code from this article into a gist.